프림 알고리즘은 크루스칼 알고리즘과 함께 어떤 그래프가 주어졌을 때 그 그래프에서 최소신장트리(MST) 를 찾아내는 알고리즘 입니다. 최소신장트리에 대한 개념은 앞에 포스트했던 크루스컬 알고리즘에서 정리하였으니 참고하시기 바랍니다.
https://buganddog.tistory.com/2
[알고리즘 , 파이썬] 크루스칼 알고리즘 - 1
이번 포스트에서는 크루스칼 알고리즘을 다루도록 하겠습니다 긴호흡의 글이 될 것 같아 3개의 글로 나눠 포스트 하도록 하겠습니다. 이번 포스트에서는 크루스칼알고리즘의 개념을 이해하는데 중점을 두고 구현은..
buganddog.tistory.com
크루스칼 알고리즘에서 먼저 간선을 선택하고 그다음 노드를 하나씩 붙여가는 식이였다면 프림알고리즘은 반대로 시작 정점을 먼저 선택한 후 정점에 연결된 간선을 추가해서 하나씩 붙여나가는 방식으로 알고리즘이 진행됩니다. 말이 참 애매한데; 좀더 명확히 정리해보도록 하겠습니다.
프림 알고리즘 (Prim's algorithm)
- 대표적인 최소 신장 트리 알고리즘
- Kruskal’s algorithm (크루스칼 알고리즘), Prim's algorithm (프림 알고리즘)
- 프림 알고리즘
- 시작 정점을 선택한 후, 정점에 인접한 간선중 최소 간선으로 연결된 정점을 선택하고, 해당 정점에서 다시 최소 간선으로 연결된 정점을 선택하는 방식으로 최소 신장 트리를 확장해가는 방식
- Kruskal's algorithm 과 Prim's algorithm 비교
- 둘다, 탐욕 알고리즘을 기초로 하고 있음 (당장 눈 앞의 최소 비용을 선택해서, 결과적으로 최적의 솔루션을 찾음)
- Kruskal's algorithm은 가장 가중치가 작은 간선부터 선택하면서 MST를 구함
- Prim's algorithm은 특정 정점에서 시작, 해당 정점에 연결된 가장 가중치가 작은 간선을 선택, 간선으로 연결된 정점들에 연결된 간선 중에서 가장 가중치가 작은 간선을 택하는 방식으로 MST를 구함.
프림알고리즘의 동작을 이해 하기위해선 다음 5단계만 기억하시면 됩니다!
- 임의의 정점을 선택, '연결된 노드 집합'에 삽입
- 선택된 정점에 연결된 간선들을 간선 리스트를 만들어서 리스트에 삽입
- 간선 리스트에서 최소 가중치를 가지는 간선부터 추출해서,
- 해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 이미 들어 있다면, 스킵! (cycle 발생을 막기 위함)
- 해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 들어 있지 않으면, 해당 간선을 선택하고, 해당 간선 정보를 '최소 신장 트리'에 삽입
- 추출한 간선은 간선 리스트에서 제거
- 간선 리스트에 더 이상의 간선이 없을 때까지 3-4번을 반복
처음에는 간선 리스트가 무엇이며, 연결된 노드 집합이라는 건 무엇인지 감이 잘 오지 않으실 겁니다.
이러한 세부적인 부분들은 후에 구현 부분에서 다루기로하고, 우선 프림알고리즘의 동작방식에 대한 큰 개념을 잡는것을 목표로 하고 이를 그림으로 확인해 보도록하겠습니다.

먼저 시작단계입니다. 위에서 5단계를 잘 염두하고 그래프를 보도록하겠습니다.
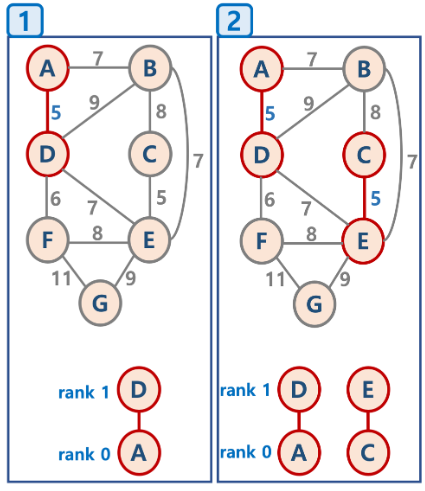
시작은 임의의 정점을 선택하는 것에서 시작합니다.
여기서는 A라는 정점을 선택했군요!
그림상에서 보이지는 않지만, 선택한 A 노드를 '연결된 노드집합' 으로 정의된 자료구조에 넣고 선택된 정점에 연결된
간선들. 또한 '연결된 간선 리스트' 라는 자료구조를 정의해서 그안에 넣어 두도록 합시다.
앞서 말씀드렸듯이. 어떻게 넣는지에 대해서는 생각을 잠시 미루고, 큰 개념을 우선적으로 보겠습니다.
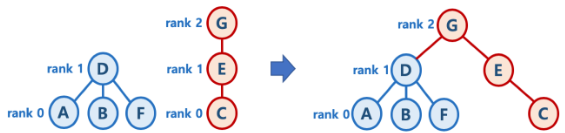
( 위 그림에서는 리스트에 넣어진 간선은 빨간색, MST에 들어간 노드와 간선들은 파란색으로 표시해줍니다 )
그림에서는 노드 A가 선택되고 A와 연결된 가중치 5, 7인 간선 2개가 간선리스트에 추가가되고, 따라서 리스트에 저장된 간선중 가중치가 최소인 (5 ,A->D) 간선을 꺼내서 조사를 합니다. (3단계 과정)
- 해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 이미 들어 있다면, 스킵! (cycle 발생을 막기 위함)
- 해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 들어 있지 않으면, 해당 간선을 선택하고, 해당 간선 정보를 '최소 신장 트리'에 삽입
현재 그림에서는 간선에 연결된 노드 D 가 연결된 노드집합에 속해 있지 않으므로 노드 D를 연결된 노드 집합에 추가해 줍니다! 그 후 조사했던 간선 (5 ,A->D) 는 연결된 간선리스트에서 제거해줍니다!
동작방식이 조금은 이해 되시나요?
이와 같은 과정을 계속해서 반복하여 더 이상 연산가능한 간선이 없을 때 까지 계속해서 반복하는것이 프림알고리즘 입니다! 계속해서 확인해 보도록 하겠습니다.

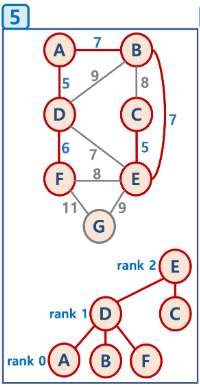
노드 D와 연결된 간선들 리스트에 저장 -> 리스트에서 가중치 최소인 간선 (5, D->F) 추출 -> 연결된 노드집합에 F가 없으므로 노드집합에 추가 -> (5, D->F) 간선을 '최소 신장 트리'에 삽입 -> 간선리스트에서 (5, D->F)제거
이제 좀 더 감이 확실히 잡히는 느낌입니다. 이제 나머지 동작그림을 한눈에 봐보도록 하겠습니다
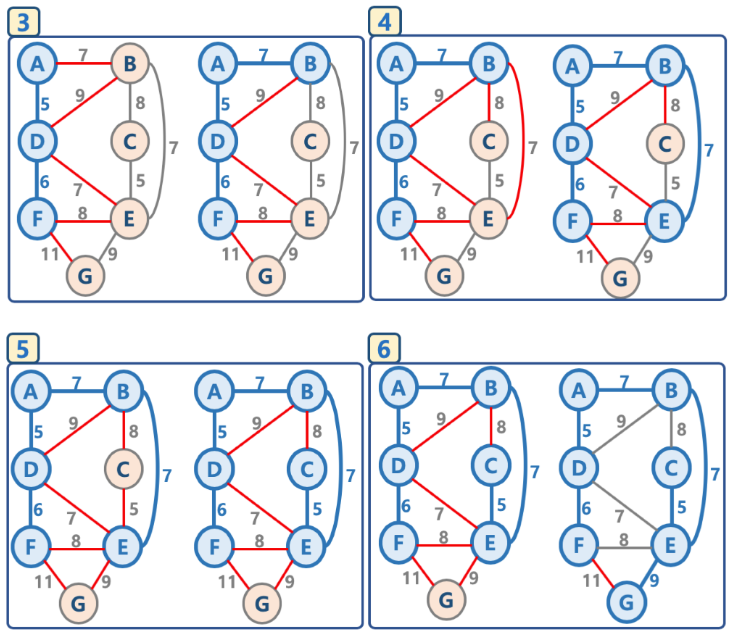
마지막 6번에서 리스트에 저장된 간선들(빨간색 간선)을 모두 조사를 하지만 (9,E-G)를 잇고 나서는 모든 노드들이
연결되어있고, 최소신장트리가 완성되어 있으므로 그 이외의 나머지 간선들은 위 단계3 에서 정의한 조건
- 해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 이미 들어 있다면, 스킵! (cycle 발생을 막기 위함) 을
만족하지 못하기 때문에 리스트에 추가되는 과정없이 스킵이 됩니다! 이렇게 모두 스킵이 되어 더이상 연산을 진행할 간선이 없게 된다면 알고리즘이 종료되는 것입니다.
여기까지 이해를 하셨다면 프림알고리즘을 구현하는데 있어서 필요한 동작개념을 완벽히 이해를 하신겁니다 ㅎ
다음 포스트에서는 이 개념을 염두해서 파이썬으로 프림 알고리즘을 구현해 보도록 하겠습니다.
'알고리즘 > 알고리즘 이론' 카테고리의 다른 글
| [알고리즘, C++]백 트래킹 (Backtracking) (0) | 2020.05.09 |
|---|---|
| [알고리즘, 파이썬] 프림 알고리즘 - 2 (0) | 2020.04.27 |
| [알고리즘, 파이썬] 크루스칼 알고리즘 - 3 (0) | 2020.04.23 |
| [알고리즘, 파이썬] 크루스칼 알고리즘 - 2 (0) | 2020.04.23 |
| [알고리즘 , 파이썬] 크루스칼 알고리즘 - 1 (0) | 2020.04.23 |