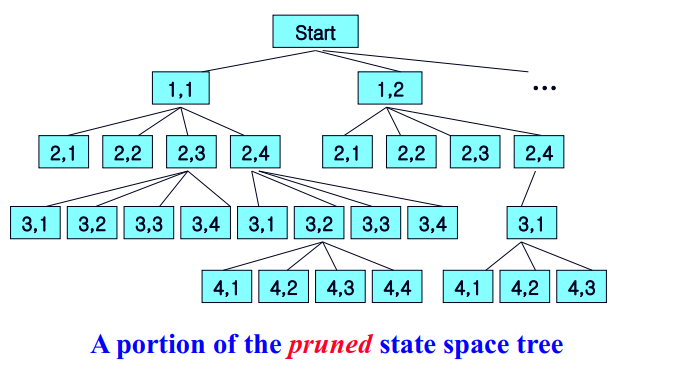
이번 포스트에서는 Branch and Bound(분기한정법) 기법에 대해서 다루도록 하겠습니다.
분기한정법은 이전 포스트에서 다루었던 backtrackingr과 매우 유사하지만, backtracking이 존재할 수 있는 모든 알고리즘의 해를 찾는 방법이라면, branch and Bound기법은 마찬가지로 상태공간 트리를 구축하여 문제를 해결하지만, 궁극적으로 모든 가능한 해를 다 고려하여 최적의 해를 찾는다는 점이 큰 차이점이라 할 수 있겠습니다.

Branch and Bound 기법은 크게 두가지 단계로 나뉩니다.
1. 어떤 노드에 도달하였을 때, 해당 노드가 promising 한지 아닌지를 판단하기 위해 노드의 바운드를 계산하는 일
2. 헌재 노드의 바운드가 이제까지 찾은 best solution보다 작다면, 그 노드는 non-Promising 하다 판단, pruning.
이러한 방법은 이전 벡트래킹 포스트에서 다루었던 0-1 Knapsack Problem의 문제와 매우 유사한 형태 입니다.
다만 이전 포스트에서 다루었던것은 이러한 분기한정법을 깊이우선 탐색을 통해 Backtracking으로 해결하였다면, 이번 포스트에서는 Breadth-First-Search , Best-First Search 탐색 방법으로 분기한정법을 다루도록 하겠습니다.
너비우선검색(Breadth-First Search) |
이 방식은 분기한정법을 너비우선 탐색으로 진행한 방법입니다.
말 그대로 루트노드를 먼저 검색하고, 다음level에 있는 모든 노드를 왼쪽에서 오른쪽순으로 검색한다음, 마찬가지로 다음 레벨에 대해서도 이와 같은 순서로 탐색을 진행하며 최적의 해를 찾아나가는 방식입니다. 그림을 통해 진행과정을 하나하나 알아보도록 하겠습니다.

bound를 계산하는 방식은 이전 backtracking 포스트의 0-1 knapsack문제에서 다루었기 때문에 자세히 다루지 않겠습니다. 첫번째 루트노드 탐색에선, 현재가지 찾은 best solution이 0, bound값을 계산하였을 때 115의 값을 가집니다. 따라서 bests olution보다 bound값이 크므로 promising하다 판단하여 해당 노드를 queue에 삽입하고, 그 자식노드들에 대한 탐색을 진행합니다. 이와같은 연산을 Queue가 empty가 될 때까지 탐색을 진행합니다.

이전 queue에 저장된 Node0을 Pop하고, 그 자식노드들에 대해서 탐색을 진행합니다. Node1, Node2는 각각 해당 레벨에 해당하는 item(1번 item)을 넣기로 한 경우와 넣지 않기로 한 경우를 표현한 것입니다. 먼저 물건을 넣기로 한 경우인 Node1의 profit은 40으로 현재까지 중에 가장 best solution입니다. 또한 각 노드의 bound값을 계산하면 각각 115, 82이고 이는 현재 best_solution인 40보다 큰 bound값이므로 모두 queue에 삽입합니다.

마찬가지로 이전 queue에 저장된 {Node0, Node1}을 모두 pop하여 그 자식노드들에 대해서 profit 값과 bound 값을 계산합니다. 계산결과 현재까지의 최적의 해는 Node3의 값인 70이며, Node6의 bound값은 60으로 현재까지의 최적의 값보다 bound값이 작으니 non-promising하다는 것을 알 수 있습니다. 따라서 Node6의 자식노드에 대해서는 더이상 탐색할 필요가 없으니 이를 제외한 나머지 노드들 만을 Queue에 삽입합니다.


마지막 레벨탐색에서 Node15는 item4를 넣을경우 무게가 초과 되기때문에 non-promising하고 그 외
Queue가 모두 빌 때까지 마찬가지로 연산을 진행하면 위와같이 best_solution이 90임을 알 수 있습니다.
이제 상태공간트리와 알고리즘의 흐름을 파악하였으니 이를 토대로 Breadth-First-Search 방식으로 수도코드를 작성해 보도록 하겠습니다. 재귀(recursive)로 구현하기에는 상당히 복잡하므로 queue를 이용하도록 하겠습니다
Best-First-Search(최고우선탐색)
|

이 방법은 최정의 해에 더 빨리 도달하기 위한 전략입니다. bound 값이 큰것이 더 좋은 결과값을 낼 확률이 높다는 것에 기반하여 너비우선 탐색과같이 순차적으로 검색하는 것이 아닌, 우선순위 큐를 사용하여 바운드 값이 큰 순서대로 탬색을 진행합니다. 그림을 통해서 동작방식을 살펴보도록 하겠습니다. 루트노드를 삽입하는 부분은 위에 그림과 겹치므로, level2 탐색부터 보겠습니다.

우선 순위 큐에 의해서 큐에는 bound값이 큰것이 먼저 나올 수 있도록 정렬되어 있습니다. 이제까지의 bestsolution은 70이며, 다음에 탐색할 노드는 바운드 값이 가장 큰 Node3의 자식노드입니다.

탐색결과 Node3의 자식노드인 Node5는 무게초과로 Non-promising, Node6는 bound값이 80으로 아직까진 현재 best_solution인 70보다는 값이 크므로 promising으로 판단하고 우선순위 큐에 넣어줍니다. 다음에 탐색할 노드는 bound값이 가장 큰 Node4의 자식노드입니다.

Node4의 자식노드인 Node7을 검색한 결과, 현재까지의 bestSolution은 90으로 갱신됩니다. Node7의 bound는 90보다 크므로 큐에 삽입하고, Node8의 바운드값은 90보다 작으므로 non-Promising 하다 판단하여 큐에 넣지 않습니다.

이런식으로 순차적으로 탐색을 진행하면, 최종적으로 큐에 남은 Node2, Node6는 best_solution보다 작은 bound값을 가지고 있으므로 non-Promising이라 판단, 따라서 더이상 그 자식노드들을 살펴보지 않고 그대로 탐색을 종료하게 됩니다. 딱 봐도 탐색 과정이 이전 너비우선 탐색기반 bound & branch법 보다 상당히 줄어든 것을 확인할 수 있습니다.
이와 같이 최고우선탐색 기법을 사용하면, 너비우선 탐색에 비해서 일반적으로 검색 성능이 좋아집니다.
이제 동작방식을 확인하였으니 마찬가지로 수도코드를 작성해 보겠습니다.
(sudo 코드가 아닌 실전 코드를 확인하고 싶으시다면 (여길 참조하시면 좋을 것 같습니다
-http://yimoyimo.tk/Dynamic,Branch-and-bound-Knapsack/#branch-and-bound--01-%EB%B0%B0%EB%82%AD%EC%B1%84%EC%9A%B0%EA%B8%B0-best--first-search)
The Traveling SalesPerson Problem (with BFS_B&B)
이제 마지막으로 TSP문제를 Best-First-Search 기반 Branch Bound방식으로 해결해 보겠습니다.
T.S.P문제는 다음과 같습니다.
- 외판원이 어느 한도시에서 출발하여, 다른 도시들을 각각 한번씩만 방문하고
자기 도시로 돌아오는 가장 짧은 일주경로를 걸정하는 문제 - 일반적으로 이 문제는 음이 아닌 가중치가 있는 방향성 그래프를 입력값으로 받는다
- 여러 개의 일주여행경로 중에서 길이가 최소가 되는 경로가 최적의 경로가 된다.

이 문제를 분기한정법으로 해결하기 위해서는 먼저
1. 상태공간트리의 노드가 어떤 식으로 표현이 되어야 하는가 정의
2. 어떤 노드의 서브트리를 탐색했을 때 얻을 수 있는 최적의 bound값을 계산하는 방법
이 두가지에 대해서 생각해야 합니다.
먼저 상태공간트리가 어떤 식으로 정의 될 지 생각해보면 다음과 같습니다.

아마도 뻗어나가는 경로를 표현할 수 있어야 하므로, level 1은 출발지, level2는 출발지에서 다음 노드 까지의 경로..
이런식으로 노드를 표현할 수 있을 겁니다. 이런 식으로 뻗어나가서 단말노드(leaf node)에 도달하게 되면 비로소 완전한 일주경로를 가지게 되는 것이죠
따라서 우리는 단말노드에 있는 일주 경로를 모두 검사하여 그중에서 가장 길이가 짧은 일주경로를 찾으면 됩니다. 위 그림에서 만약 경로에 저장되어 있는 노드가 n-1개가 되면 더 이상 뻗어 나갈 필요가 없는데, 그 이유는 어차피 n번째 노드를 방문한다면 자연스럽게 처음의 노드로 회귀해야 때문입니다.
이제 상태공간 트리를 생각해 보았으니 bound값을 계산할 수 있는 방법에 대해서 생각해 봅시다.
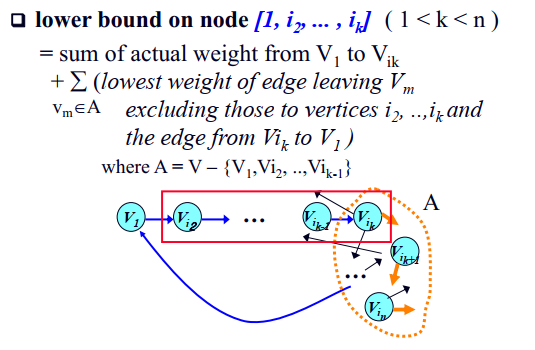
상태 공간트리에서 k번째 레벨에 있는 노드들은 k+1번쨰 정점을 방문한 상태를 의미합니다.
먼저 위 그림을 하나하나 해석해보겠습니다.
[1, ..., k]의 여행경로를 가진 노드의 한계치는 다음과 같이 계산할 수 있습니다.
- A = V - ([1, .., K] 경로에 속한 모든 노드의 집합) -> 그림상으로 주황색 점선 안
- bound = [1,...,k] 경로의 총 가중치 합 _
+ v_k에서 A에 속한 정점으로 가는 것중 최소의 cost 값
+ (시그마)vi를 제외한 정점들 중 (빨간색 박스안 정점들을 제외한 정점들 중) cost가 최소인 것들의 합
(말이 상당히 애매하지만, 밑에서 그림과 설명하도록하겠습니다)
글로 정의하였지만 아직 잘 와닿지 않을 수 있습니다.
이 과정을 아래 예제를 통해서 확인해 보도록 하겠습니다.


루트노드의 하한 구하는 방법:
어떤 일주경로라도, 각 정점을 최소한 한번은 떠나야 하므로, 각 정점을 떠나는 이음선의 cost 최소값의 합이 bound값이 됩니다. 즉 각각의 경우중 최소의 값만 다 더하면, bound 값은 4 + 7 + 4 + 2+ 4 = 21 입니다.
단, 여기서 주의할 점은 bound값은 "이러한 가중치를 가지는 경로가 존재 한다는 것"이 아니라 이보다 더 cost가 작은 경로가 존재할 수 없다는 의미를 가지는 것입니다. 그래서 하한(lower bound)라는 말을 사용하는 겁니다.
이제 각 레벨별로 어떻게 알고리즘이 동작하는지 살펴보도록 하겠습니다.
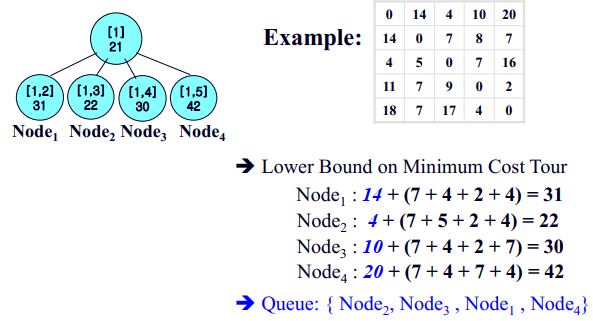
먼저 bound계산 알고리즘에 대한 좀더 자세한 이해를 위해 [1,2]를 선택했을 때의 bound값 계산과정을 살펴보도록 하겠습니다.

이미 v2를 선택하였음으로, v1->v2의 비용은 이음선의 가중치인 14가 됩니다. 나머지는 앞서 설명한대로 구해보면
- v2에서 A에 속한 값 중 가중치 중에 (7, 8, 7) 최소인값 : 7
- v3에서 전체에서 v2를 제외한(4, 7, 16) 가중치 중 최소인 값 : 4
- v4에서 전체에서 v2를 제외한(11, 9, 2) 가중치 중 최소인 값 : 2
- v5에서 전체에서 v2를 제외한(18, 17, 4) 가중치 중 최소인 값 : 4
- [1,2]노드의 bound값 : 31
따라서 이런 방식으로 나머지 노드들에 대해서 계산을 해보면 다음과 같은 상태가 됩니다.
마지막으로 한번더 노드 [1,2,3]을 선택한 경우의 bound값을 구해보도록 하겠습니다.

이미 v2와 v3를 선택하였으므로 v1->v2->v3의 cost는 14 + 7 = 21이 됩니다.
나머지는 앞서 설명한 방법과 동일하게 계산해 보면
- v1 -> 14
- v2 -> 7
- v3 에서 A에 속한 값중 (7, 16)가중치가 최소인 값 : 7
- v4 에서 전체에서 v2, v3를 제외한 값중 (11,2) 가중치가 최소인 값 : 2
- v5 에서 전체에서 v2, v3를 제외한 값중 (18, 4) 가중치가 최소인 값: 4 '
- [1,2,3]노드의 bound값 : 14 + 7 + 7 + 2 + 4 = 34
따라서 이런 방식으로 나머지 노드들에 대해서 계산을 해보면 레벨3의 상태공간트리는 다음과 같은 상태가 됩니다. 위에 예시를 [1,2,3]을 선택한 경우를 들었지만 우선순위 큐에 의해 [1,3]을 선택한 경로의 자식노드부터 탐색을 시작하는군요;

이와 같이 계속 계산해 나가다 보면 결국 최종적으로 단말노드(level n-1)까지 계산할 수 있습니다.

드디어 첫번째 best_solution값이 나왔습니다. 이제 여태 해왔던 것처럼 Queue를 하나씩 꺼내어 bound값을 bestSolution과 비교하여 bound값이 더 작다면(최적이라면) 그대로 탐색하지않고 종료를, 아니라면 해당노드의 밑으로 탐색을 진행하고, 더 좋은 best solution값이 나오면 값을 갱신하는 방법으로 진행해 나가면 최종해를 구할 수 있습니다

결국 큐에 있는 모든 노드들의 bound값이 최적의 해인 30보다 모두 큰 값이므로 최적의 경로는 30의 가중치를 가진 v1 -> v4 -> v5 -> v2 -> v1 경로인것을 구할 수 있습니다. 이제 동작방식을 이해하였으니 sudo코드를 작성해 보도록 하겠습니다.
자세한 알고리즘은 생략하였지만 결론은 branch and bound 기법으로 문제를 접근하여도 여전히 시간복잡도가 지수적이거나 그보다 못하다는 점입니다. 즉 n=40정도가 된다면 문제를 풀 수 없는 것과 다름이 없다고 할 수 있습니다.
이 문제는 아직까지 최적의 알고리즘이 밝혀지지 않은 문제중 하나인데요, 오늘은 이렇게 해서 B&B방식을 3개의 예제를 통해서 알아보았습니다. 이상으로 포스트 마치겠습니다.
'알고리즘 > 알고리즘 이론' 카테고리의 다른 글
| [알고리즘, C++]백 트래킹 (Backtracking) (0) | 2020.05.09 |
|---|---|
| [알고리즘, 파이썬] 프림 알고리즘 - 2 (0) | 2020.04.27 |
| [알고리즘 , 파이썬] 프림 알고리즘 - 1 (0) | 2020.04.27 |
| [알고리즘, 파이썬] 크루스칼 알고리즘 - 3 (0) | 2020.04.23 |
| [알고리즘, 파이썬] 크루스칼 알고리즘 - 2 (0) | 2020.04.23 |