이번 포스트에서는 Branch and Bound(분기한정법) 기법에 대해서 다루도록 하겠습니다.
분기한정법은 이전 포스트에서 다루었던 backtrackingr과 매우 유사하지만, backtracking이 존재할 수 있는 모든 알고리즘의 해를 찾는 방법이라면, branch and Bound기법은 마찬가지로 상태공간 트리를 구축하여 문제를 해결하지만, 궁극적으로 모든 가능한 해를 다 고려하여 최적의 해를 찾는다는 점이 큰 차이점이라 할 수 있겠습니다.
'
Branch and Bound 기법은 크게 두가지 단계로 나뉩니다.
1. 어떤 노드에 도달하였을 때, 해당 노드가 promising 한지 아닌지를 판단하기 위해 노드의 바운드를 계산하는 일
2. 헌재 노드의 바운드가 이제까지 찾은 best solution보다 작다면, 그 노드는 non-Promising 하다 판단, pruning.
이러한 방법은 이전 벡트래킹 포스트에서 다루었던 0-1 Knapsack Problem의 문제와 매우 유사한 형태 입니다.
다만 이전 포스트에서 다루었던것은 이러한 분기한정법을 깊이우선 탐색을 통해 Backtracking으로 해결하였다면, 이번 포스트에서는 Breadth-First-Search , Best-First Search 탐색 방법으로 분기한정법을 다루도록 하겠습니다.
너비우선검색(Breadth-First Search)
이 방식은 분기한정법을 너비우선 탐색으로 진행한 방법입니다.
말 그대로 루트노드를 먼저 검색하고, 다음level에 있는 모든 노드를 왼쪽에서 오른쪽순으로 검색한다음, 마찬가지로 다음 레벨에 대해서도 이와 같은 순서로 탐색을 진행하며 최적의 해를 찾아나가는 방식입니다. 그림을 통해 진행과정을 하나하나 알아보도록 하겠습니다.
0번째 level 탐색
bound를 계산하는 방식은 이전 backtracking 포스트의 0-1 knapsack문제에서 다루었기 때문에 자세히 다루지 않겠습니다. 첫번째 루트노드 탐색에선, 현재가지 찾은 best solution이 0, bound값을 계산하였을 때 115의 값을 가집니다. 따라서 bests olution보다 bound값이 크므로 promising하다 판단하여 해당 노드를 queue에 삽입하고, 그 자식노드들에 대한 탐색을 진행합니다. 이와같은 연산을 Queue가 empty가 될 때까지 탐색을 진행합니다.
1번째 level 탐색
이전 queue에 저장된 Node0을 Pop하고, 그 자식노드들에 대해서 탐색을 진행합니다. Node1, Node2는 각각 해당 레벨에 해당하는 item(1번 item)을 넣기로 한 경우와 넣지 않기로 한 경우를 표현한 것입니다. 먼저 물건을 넣기로 한 경우인 Node1의 profit은 40으로 현재까지 중에 가장 best solution입니다. 또한 각 노드의 bound값을 계산하면 각각 115, 82이고 이는 현재 best_solution인 40보다 큰 bound값이므로 모두 queue에 삽입합니다.
2번째 레벨 탐색
마찬가지로 이전 queue에 저장된 {Node0, Node1}을 모두 pop하여 그 자식노드들에 대해서 profit 값과 bound 값을 계산합니다. 계산결과 현재까지의 최적의 해는 Node3의 값인 70이며, Node6의 bound값은 60으로 현재까지의 최적의 값보다 bound값이 작으니 non-promising하다는 것을 알 수 있습니다. 따라서 Node6의 자식노드에 대해서는 더이상 탐색할 필요가 없으니 이를 제외한 나머지 노드들 만을 Queue에 삽입합니다.
3번째 레벨 탐색4번쨰 레벨 탐색
마지막 레벨탐색에서 Node15는 item4를 넣을경우 무게가 초과 되기때문에 non-promising하고 그 외
Queue가 모두 빌 때까지 마찬가지로 연산을 진행하면 위와같이 best_solution이 90임을 알 수 있습니다.
이제 상태공간트리와 알고리즘의 흐름을 파악하였으니 이를 토대로 Breadth-First-Search 방식으로 수도코드를 작성해 보도록 하겠습니다. 재귀(recursive)로 구현하기에는 상당히 복잡하므로 queue를 이용하도록 하겠습니다
Best-First-Search(최고우선탐색)
이 방법은 최정의 해에 더 빨리 도달하기 위한 전략입니다. bound 값이 큰것이 더 좋은 결과값을 낼 확률이 높다는 것에 기반하여 너비우선 탐색과같이 순차적으로 검색하는 것이 아닌, 우선순위 큐를 사용하여 바운드 값이 큰 순서대로 탬색을 진행합니다. 그림을 통해서 동작방식을 살펴보도록 하겠습니다. 루트노드를 삽입하는 부분은 위에 그림과 겹치므로, level2 탐색부터 보겠습니다.
level2 탐색
우선 순위 큐에 의해서 큐에는 bound값이 큰것이 먼저 나올 수 있도록 정렬되어 있습니다. 이제까지의 bestsolution은 70이며, 다음에 탐색할 노드는 바운드 값이 가장 큰 Node3의 자식노드입니다.
level3 탐색
탐색결과 Node3의 자식노드인 Node5는 무게초과로 Non-promising, Node6는 bound값이 80으로 아직까진 현재 best_solution인 70보다는 값이 크므로 promising으로 판단하고 우선순위 큐에 넣어줍니다. 다음에 탐색할 노드는 bound값이 가장 큰 Node4의 자식노드입니다.
Node4의 자식노드인 Node7을 검색한 결과, 현재까지의 bestSolution은 90으로 갱신됩니다. Node7의 bound는 90보다 크므로 큐에 삽입하고, Node8의 바운드값은 90보다 작으므로 non-Promising 하다 판단하여 큐에 넣지 않습니다.
탐색 종료
이런식으로 순차적으로 탐색을 진행하면, 최종적으로 큐에 남은 Node2, Node6는 best_solution보다 작은 bound값을 가지고 있으므로 non-Promising이라 판단, 따라서 더이상 그 자식노드들을 살펴보지 않고 그대로 탐색을 종료하게 됩니다. 딱 봐도 탐색 과정이 이전 너비우선 탐색기반 bound & branch법 보다 상당히 줄어든 것을 확인할 수 있습니다.
이와 같이 최고우선탐색 기법을 사용하면, 너비우선 탐색에 비해서 일반적으로 검색 성능이 좋아집니다.
이제 마지막으로 TSP문제를 Best-First-Search 기반 Branch Bound방식으로 해결해 보겠습니다.
T.S.P문제는 다음과 같습니다.
외판원이 어느 한도시에서 출발하여, 다른 도시들을 각각 한번씩만 방문하고 자기 도시로 돌아오는 가장 짧은 일주경로를 걸정하는 문제
일반적으로 이 문제는 음이 아닌 가중치가 있는 방향성 그래프를 입력값으로 받는다
여러 개의 일주여행경로 중에서 길이가 최소가 되는 경로가 최적의 경로가 된다.
이 문제를 분기한정법으로 해결하기 위해서는 먼저
1. 상태공간트리의 노드가 어떤 식으로 표현이 되어야 하는가 정의
2. 어떤 노드의 서브트리를 탐색했을 때 얻을 수 있는 최적의 bound값을 계산하는 방법
이 두가지에 대해서 생각해야 합니다.
먼저 상태공간트리가 어떤 식으로 정의 될 지 생각해보면 다음과 같습니다.
TSP space-state-tree
아마도 뻗어나가는 경로를 표현할 수 있어야 하므로, level 1은 출발지, level2는 출발지에서 다음 노드 까지의 경로..
이런식으로 노드를 표현할 수 있을 겁니다. 이런 식으로 뻗어나가서 단말노드(leaf node)에 도달하게 되면 비로소 완전한 일주경로를 가지게 되는 것이죠
따라서 우리는 단말노드에 있는 일주 경로를 모두 검사하여 그중에서 가장 길이가 짧은 일주경로를 찾으면 됩니다. 위 그림에서 만약 경로에 저장되어 있는 노드가 n-1개가 되면 더 이상 뻗어 나갈 필요가 없는데, 그 이유는 어차피 n번째 노드를 방문한다면 자연스럽게 처음의 노드로 회귀해야 때문입니다.
이제 상태공간 트리를 생각해 보았으니 bound값을 계산할 수 있는 방법에 대해서 생각해 봅시다.
상태 공간트리에서 k번째 레벨에 있는 노드들은 k+1번쨰 정점을 방문한 상태를 의미합니다.
먼저 위 그림을 하나하나 해석해보겠습니다.
[1, ..., k]의 여행경로를 가진 노드의 한계치는 다음과 같이 계산할 수 있습니다.
- A = V - ([1, .., K] 경로에 속한 모든 노드의 집합) -> 그림상으로 주황색 점선 안
- bound = [1,...,k] 경로의 총 가중치 합 _ + v_k에서 A에 속한 정점으로 가는 것중 최소의 cost 값
+ (시그마)vi를 제외한 정점들 중 (빨간색 박스안 정점들을 제외한 정점들 중) cost가 최소인 것들의 합
(말이 상당히 애매하지만, 밑에서 그림과 설명하도록하겠습니다)
글로 정의하였지만 아직 잘 와닿지 않을 수 있습니다.
이 과정을 아래 예제를 통해서 확인해 보도록 하겠습니다.
루트노드의 bound값 계산
루트노드의 하한 구하는 방법:
어떤 일주경로라도, 각 정점을 최소한 한번은 떠나야 하므로, 각 정점을 떠나는 이음선의 cost 최소값의 합이 bound값이 됩니다. 즉 각각의 경우중 최소의 값만 다 더하면, bound 값은 4 + 7 + 4 + 2+ 4 = 21 입니다.
단, 여기서 주의할 점은 bound값은 "이러한 가중치를 가지는 경로가 존재 한다는 것"이 아니라 이보다 더 cost가 작은 경로가 존재할 수 없다는 의미를 가지는 것입니다. 그래서 하한(lower bound)라는 말을 사용하는 겁니다.
이제 각 레벨별로 어떻게 알고리즘이 동작하는지 살펴보도록 하겠습니다.
먼저 bound계산 알고리즘에 대한 좀더 자세한 이해를 위해 [1,2]를 선택했을 때의 bound값 계산과정을 살펴보도록 하겠습니다.
노드 [1,2]를 선택한 경우 bound값 계산
이미 v2를 선택하였음으로, v1->v2의 비용은 이음선의 가중치인 14가 됩니다. 나머지는 앞서 설명한대로 구해보면
- v2에서 A에 속한 값 중 가중치 중에 (7, 8, 7) 최소인값 : 7
- v3에서 전체에서 v2를 제외한(4, 7, 16) 가중치 중 최소인 값 : 4
- v4에서 전체에서 v2를 제외한(11, 9, 2) 가중치 중 최소인 값 : 2
- v5에서 전체에서 v2를 제외한(18, 17, 4) 가중치 중 최소인 값 : 4
- [1,2]노드의 bound값 : 31
따라서 이런 방식으로 나머지 노드들에 대해서 계산을 해보면 다음과 같은 상태가 됩니다.
level1 에서 각각의 bound 값 계산
마지막으로 한번더 노드 [1,2,3]을 선택한 경우의 bound값을 구해보도록 하겠습니다.
- v5 에서 전체에서 v2, v3를 제외한 값중 (18, 4) 가중치가 최소인 값: 4 '
-[1,2,3]노드의 bound값 : 14 + 7 + 7 + 2 + 4 = 34
따라서 이런 방식으로 나머지 노드들에 대해서 계산을 해보면 레벨3의 상태공간트리는 다음과 같은 상태가 됩니다. 위에 예시를 [1,2,3]을 선택한 경우를 들었지만 우선순위 큐에 의해 [1,3]을 선택한 경로의 자식노드부터 탐색을 시작하는군요;
level3 state-space-tree
이와 같이 계속 계산해 나가다 보면 결국 최종적으로 단말노드(level n-1)까지 계산할 수 있습니다.
드디어 첫번째 best_solution값이 나왔습니다. 이제 여태 해왔던 것처럼 Queue를 하나씩 꺼내어 bound값을 bestSolution과 비교하여 bound값이 더 작다면(최적이라면) 그대로 탐색하지않고 종료를, 아니라면 해당노드의 밑으로 탐색을 진행하고, 더 좋은 best solution값이 나오면 값을 갱신하는 방법으로 진행해 나가면 최종해를 구할 수 있습니다
결국 큐에 있는 모든 노드들의 bound값이 최적의 해인 30보다 모두 큰 값이므로 최적의 경로는 30의 가중치를 가진 v1 -> v4 -> v5 -> v2 -> v1 경로인것을 구할 수 있습니다. 이제 동작방식을 이해하였으니 sudo코드를 작성해 보도록 하겠습니다.
자세한 알고리즘은 생략하였지만 결론은 branch and bound 기법으로 문제를 접근하여도 여전히 시간복잡도가 지수적이거나 그보다 못하다는 점입니다. 즉 n=40정도가 된다면 문제를 풀 수 없는 것과 다름이 없다고 할 수 있습니다.
이 문제는 아직까지 최적의 알고리즘이 밝혀지지 않은 문제중 하나인데요, 오늘은 이렇게 해서 B&B방식을 3개의 예제를 통해서 알아보았습니다. 이상으로 포스트 마치겠습니다.
사실 백 트래킹이라는 것은 알고리즘이라기 보단 어떤 문제를 풀기위한 전략? 에 가까운데요,
어떤 제약조건 만족 문제에서 해를 찾기 위한 전략으로 백 트래킹(backtracking) or 퇴각 검색(backtrack)으로 부릅니다.
해를 찾기 위해, 후보군에 제약 조건을 점진적으로 체크하다가, 해당 후보군이 제약 조건을 만족할 수 없다고 판단되는 즉시 backtrack (다시는 이 후보군을 체크하지 않을 것을 표기)하고, 바로 다른 후보군으로 넘어가며, 결국 최적의 해를 찾는 방법입니다.
실제 구현시, 고려할 수 있는 모든 경우의 수 (후보군)를 상태공간트리(State Space Tree)를 통해 표현
(반드시 트리형태로 만들 필요는 없습니다, 컨셉상 트리를 의미, 뒤에 예제와 함께 설명드리겠습니다. )
각 후보군을 DFS(깊이 우선 탐색) 방식으로 확인
상태 공간 트리를 탐색하면서, 제약이 맞지 않으면 해의 후보가 될만한 다른 곳으로 바로 넘어가서 탐색
Promising: 해당 루트가 조건에 맞는지를 검사하는 기법
Pruning (가지치기): 조건에 맞지 않으면 포기하고 다른 루트로 바로 돌아서서, 탐색의 시간을 절약하는 기법
즉, 다시한번 요약하자면 백트래킹은 트리 구조를 기반으로 DFS로 깊이 탐색을 진행하면서 각 루트에 대해 조건에 부합하는지 체크(Promising - 솔루션이 될수 있는지), 만약 해당 트리(나무)에서 조건에 맞지않는 노드는 더 이상 DFS로 깊이 탐색을 진행하지 않고, 가지를 쳐버림 (Pruning - 이 노드 아래의 모든 값들은 탐색할 필요가 없다) 라는 겁니다.
글로봤을 때는 무슨 말인지 잘 와닿지 않겠지만, 예제를 풀다보면 이것들이 무슨 의미인지 좀더 이해가 쉬울겁니다. 이제 백 트래킹 예제를 풀어보면서 살펴보겠습니다.
N Queen 문제
문제는 다음과 같습니다.
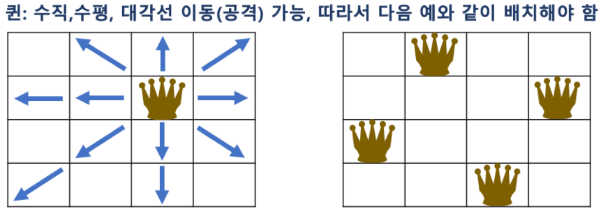
NxN 크기의 체스판에 N개의 퀸을 서로 공격할 수 없도록 배치하는 문제
퀸은 다음과 같이 이동할 수 있으므로, 배치된 퀸 간에 공격할 수 없는 위치로 배치해야 함
이 N Queen 문제는 대표적인 백 트레킹 문제입니다.
만약 4X4 크기의 체스판이라고 가정한다하면 16개의 칸중에 4개의 퀸자리를 선택하는 경우의 수만 해도
C(16,4) = 1820 , 각 행마다 하나씩 자리를 선택한다하도 4x4x4x4 = 256 가지의 경우의 수가 존재합니다.
이 모든 경우의 수를 다 참조하여 솔루션을 판단하는 것은 매우 비효율적이죠, 어디서 부터 시작해야 할지도 참 난감합니다; 우선 위에서 기술한 대로 고려할 수 있는 모든 경우의 수를 State Spae Tree로 표현해 봅시다.
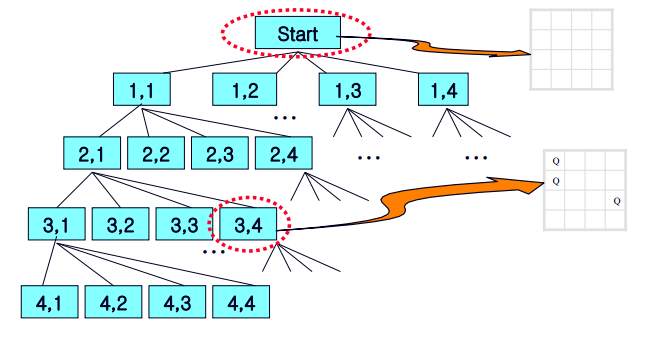
4 queens problem - State Space Tree
State Space Tree로 모든 경우의 수를 표현해본 그림입니다.
(위 그림은 개념적으로 트리형태로 표현한 것이지 구현시 반드시 트리구조를 이용해야하는 것은 아닙니다)
각 노드의 레벨은 체스판의 행번호와 같습니다. [1,1] 노드는 레벨이 1이므로 1행에 1열에 Queen을 배치하겠다는 의미입니다. 그림에서 보이는 것과 같이[3,4]은 [1,1], [2,1] 상태에서 추가적으로 [3,4] 위치에 퀸을 배치된 상태를 의미합니다.
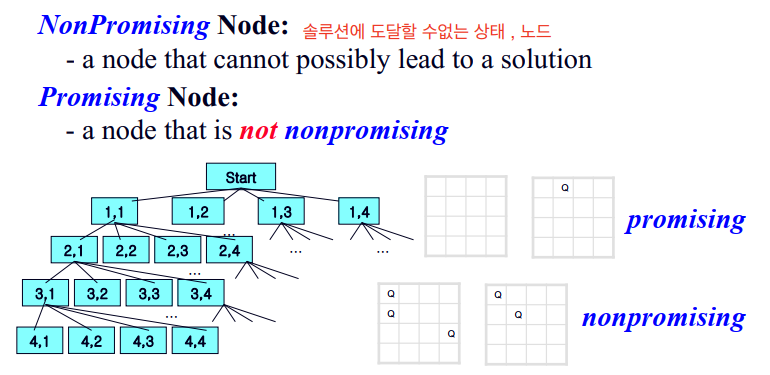
이제 Promising한 노드와 non-promising 한 경우를 살펴 봅시다.
non-promising 노드들을 puned(가지치기)한 state space tree
그림이 조금 난해합니다;
이 문제에서 promising 한것은 해당 노드가 배치된 퀸들끼리 서로의 공격범위에 들어가있지 않은 상태를 의미합니다.
예를 들면 위 그림과 같이 [1,2] 노드 상태는 아직 퀸하나만 배치되어 있으므로 promising 조건을 만족합니다.
(즉 그대로의 의미처럼 이 밑으로 솔루션이 나올수 있는 유망한 노드라는 뜻입니다.)
이럴경우해당 노드의 밑으로 계속해서 깊이 우선탐색을 진행합니다.
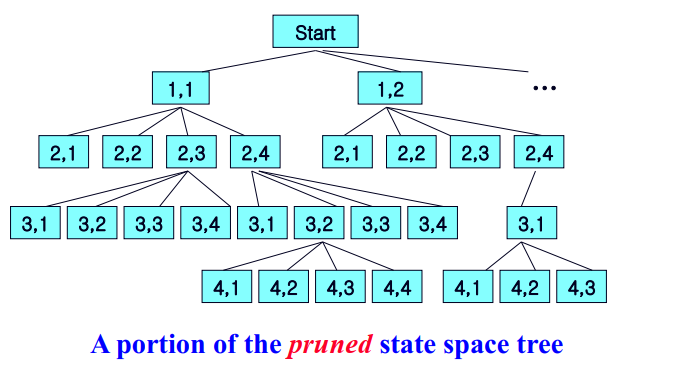
하지만 non-promising, 예를 들면 [1,1] -> [2,1] 노드처럼 이미 서로의 공격범위에 노출되어있는 상태의 노드들은
이 밑으로 경우의수를 탐색해봤자 더 이상 의미가 없습니다. 어차피 이 밑으로 탐색을 진행해도 솔루션을 만족하지 못하는 non-promising (유망하지 않은) 노드라는 것입니다. 이럴경우 [2,1] 밑으로는 탐색을 하지않고 (Pruning, 가지치기다시 backtrack 하여 다른 promising한 노드들을 찾아 조사를 시작합니다.
이제 Backtracking이란 기법이 어떻게 적용되는지 감이 오시나요? 다시한번 요약하자면 아래와 같습니다.
Backtracking
기본적으로 깊이 우선 탐색을 실행하지만, 더깊은 노드를 탐색하는 것은 현재 노드가 promising 한지에 달려있다.
만약 non-promising 하다면, backtrack하여 해당 노드의 부모노드로 돌아가 다른 노드를 search 한다
이제 본격적으로 코드를 짜기위해 Promising 한지를 판단하기 위한 규칙을 정의해 보겠습니다.
Col(i)를 i행에 위치한 퀸이 위치한 열의 번호라 정의
두 퀸이 같은 열에 위치하는 지 check 하려면 : Col(i) = Col(k) 인지 판단
두 퀸이 서로 같은 대각선에 위치하는지 check 하려면: |Col(i) - Col(k)| = i-k인지 판단
위 조건들을 check해서 두 조건에 해당하지 않는다면 해당 노드는 pomising하다고 판단할 수 있습니다.
열이 다른 것들을 제외했을 때의 promising 한 노드를 거치는 경우만 따져도 나름 대로
upperbound을 계산할 수 있으니 따져보면
Upper Bound on number of pormising nodes :
깊이 1 -> 1
깊이 2 -> n
깊이 3 -> $n\times (n-1)$ (열이 겹치는 경우를 하나 뺀경우)
깊이 4 -> $n\times (n-1)\times (n-2)$
이 모든 경우를 더하면 1+ n + n(n-1) + .. + n! 임을 알 수 있습니다.
Graph Coloring 문제
문제는 다음과 같습니다.
어떤 방향성이 없는 그래프가 주어졌을 때, 그래프의 각 노드에 m개의 색깔중 하나를 선택해서 칠함
서로 인접한 노드의 색깔은 같은 색이 되지 않도록 칠해야 한다.
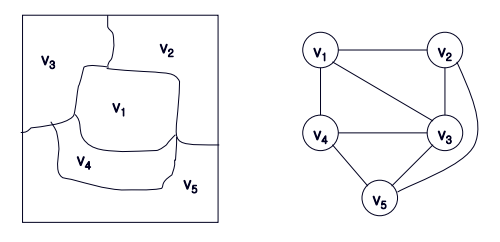
처음 접했을 때는 어떻게 접근해야 할지 막막하지만 왼쪽그림을 오른쪽과 같이 그래프로 표현할 수 있다는 점을
깨닫는 다면 쉽게 접근이 가능합니다. 이제 오른쪽 그림과 같은 그래프를 토대로 상태공간트리를 표현해보겠습니다.
각 단계를 (level을) 노드라고 정의한다면 오른쪽과 같이 상태공간 트리를 표현할 수 있습니다.
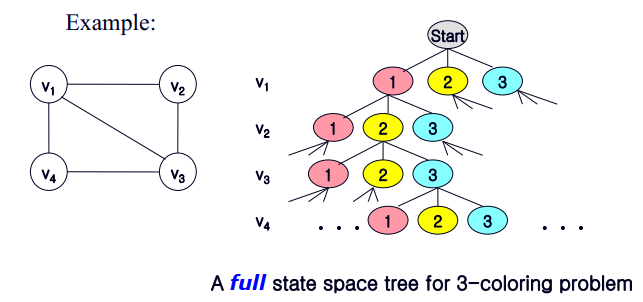
이제 state space tree를 정의하였으니 이것을 토대로 탐색을 계속 진행할지 여부를 반단하는 promising함수와
promising한 노드를 재귀적으로 탐색할 backtracking 함수를 구현하기만 하면 됩니다.
먼저 backtracking 부분을 구현해 봅시다.
backtracking 함수를 구현할 때 필요한 부분은 다음 두가지 입니다.
1. 모든 탐색이 끝났을 때 탐색을 종료하는 분기점
2. promising하다면 해당노드로 다음탐색을 진행하는 부분
위 두가지 내용을 반영하여 backtracking 함수를 구현하면 다음과 같습니다.
이제 promising 함수를 구현해봅시다.
promising한 조건을 만족하지 못하는 경우는 어떤경우가 있을까요?
아마 어느 두 노드가 서로 이어져있고, 이어져 있는 두 노드가 같은 색깔을 갖는다면그것은 promising 하지 않은 상태일 겁니다. 이를 간단한 코드로 구현한다면 다음과 같이 표현할 수 있습니다.
The 0-1 Knapsack 문제
문제는 다음과 같습니다.
배낭에 담을 수 있는 무게의 최댓값은 정해져 있다.
배낭에 넣을 물건들은 각자 무게와 가치가 정해져 있다.
짐들을 배낭에 넣을 때 가치의 합이 최대가 되도록 집을 고르는 방법을 찾아라
앞서 나온 문제들이 백 트레킹으로 특정 결과값을 구하는 문제였다면 이 문제는 앞의 문제들과는 조금 다릅니다.
바로 특정 값을 구하는 것이 아닌 조건을 만족하는 해중 가장 최적의 해를 찾는 문제라는 겁니다.
우선 state space tree를 어떻게 정의할 지 생각해봅시다.
최적의 값을 비교하기 위해선 우선 현재의 노드가 가지고 있는 현재 가치(profit)와 무게(weight)에 대한 정보가 필요할 겁니다. 하지만 이것만으로는 state space tree를 생각하기 쉽지 않습니다. 백트레킹을 구현하기 위해서는 필요없는 노드들을 pruning 할 수 있는 조건이 필요한데, 위 두 정보만으로는 이를 구현하기 어렵기 때문이죠..
따라서 다음과 같은 정보를 상태공간 트리 노드에 추가해 줍니다.
The upper bound on the maximum profit
-> 물픔을 조각내어(fraction) 채워넣는것을 허용하였을 때, 현재 노드에서 향후 얻을 수 있는 최대 이득값
말이 조금 애매할 수 있지만, 정리하자면 현재 노드의 가능성, 즉 현재상태에서 최대로 얻을 수 있는 이득값(upper bound)를 계산하여 정보를 가지고 있다면, 탐색중 만약 현재 노드의 upper bound 보다 큰 가치(profit)값을 가지고 있는 다른노드가 존재 한다면, 현재 노드 아래의 값은 더 이상 최적이 값이 아니며 탐색할 필요가 없다는 뜻이 되므로 필요없는 노드들을 pruning 하고 backtracking을 할 수 있게 되는 겁니다.
이제 profit, weight , upper bound 값을 포함한 노드를 토대로 state space tree를 정의해 봅시다.
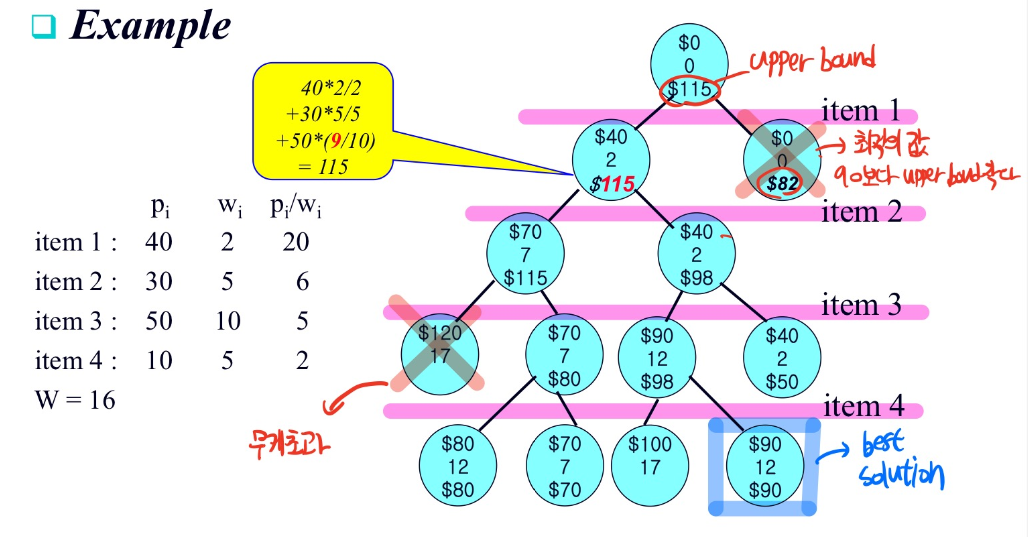
0-1 knapsack 문제 space state tree
각 물품들은 무게대비 가격이 높은 순으로 정렬되어 있으며, 최대 무게 제한은 16입니다.
upper bound란 값은 노란색 말풍선 처럼 계산 됩니다. 물품은 위에서부터 아래로 순차적으로 채워지며
item1 -> 이득 : 40 , 무게 : 2 => 누적무게: 2
item2 -> 이득 : 30 , 무게 : 5 => 누적무게: 7
item3 -> 이득 : 50 , 무게 : 10 => 누적무게: 17 -> 무게 초과로 fraction 해서 채워넣는다.
item3 -> 이득: 50 * 9/10, 무게 10* 9/10 => 누적 무게 16 , 총 upperbound profit = 115
(9/10은 (16 - 7) / item3의 무게로 구한 값)
위와 같은 계산과정을 통해서 계산이 됩니다. 따라서 위 space state tree를 기반으로
Upper bound 계산하는 부분과 promising 함수를 정의 할 수만 있다면,
이 문제를 backtracking으로 해결 할 수 있을 겁니다.
백트래킹 함수 부분:
최적의 값이 나오면 값을 갱신.
i 레벨까지 (i번쨰 아이템을 넣었을 떄) promising 하다면,
다음 아이템(i+1)을 넣거나, 넣지않았을 경우 2가지에 대해서
재귀적으로 backtracking 함수 호출
promising 함수 부분:
만약 현재 무게가 W=16을 초과한다면 false 반환,
아니라면 upper bound값을 계산해서 현재의 upperbound가 maxProfit값보다 크다면 true 반환
이로서 백트레킹에 대한 대표 예제들에 대해서 살펴보았습니다.
백트레킹으로 문제를 접근하기 위해선 먼저 space state tree를 정의해야 하며
이를 토대로 backtrack함수와 promising 함수를 정의하면 보다 쉽게 문제를 해결할 수 있음을 알아보았습니다.
다음 포스트에서는 Branch and Bound (분기 한정법) 에 대해서 알아보도록 하겠습니다.
이제 부터 위 그래프와 시작할 임의의 노드를 입력으로 받아서 최소신장트리 값을 반환하는 prim 이라는 함수를 작성해 보도록 하겠습니다!
from collections import defaultdict
from heapq import *
def prim(start_node, edges):
mst = list()
adjacent_edges = defaultdict(list)
for weight, n1, n2 in edges:
adjacent_edges[n1].append((weight, n1, n2))
adjacent_edges[n2].append((weight, n2, n1))
connected_nodes = set(start_node)
candidate_edge_list = adjacent_edges[start_node]
heapify(candidate_edge_list)
먼저 기본적인 변수 설정과 초기화 과정입니다. 최종적인 결과값(mst)를 반환할 리스트 mst,
모든 쌍방 간선들의 정보를 저장할 adjacent_edges, 연결된 노드들을 저장할 connected_nodes,
후보군 간선들을 저장할 최소우선순위 큐로 정의된 candidate_edge_list 를 정의하여 줍니다
중간에 for 문으로 시작하는 부분이 이해가 안가실 수 도 있는데, 이는 어떤 노드를 시작으로 접근하더라도 해당하는 간선 정보를 불러올 수 있도록 모든 쌍방으로 연결된 간선을 저장하는 것입니다.
입력으로 받는 myedges 그래프 같은 경우는 중복되는 간선이 없습니다.
즉 (7, `A' , 'B') 라는 간선이 저장되어 있다면 (7, `B' , 'A') 라는 간선은 저장되어 있지 않다는 말입니다.
하지만 for 문 연산을 통해 adjacent_edges에 그 쌍방의 간선정보까지 모두 저장해 줍니다.
왜 이런 짓을 하냐구요? 그래야지 어떤 노드의 값으로 접근하든 그 노드에 인접한 모든 간선의 값들을 조회할 수 있기 떄문 입니다. 만약에 그저 입력으로 들어온 그래프 값으로만 조회한다면 노드 B로 참조를 시도했을 때
(7, `B' , 'A') 라는 간선의 정보는 저장되어 있지 않기 때문에 인접 간선정보가 누락이 되버릴 겁니다.
이제 초기화까지 완료하였으니 핵심 알고리즘을 구현해 보도록 하겠습니다.
while candidate_edge_list:
weight, n1, n2 = heappop(candidate_edge_list)
if n2 not in connected_nodes:
connected_nodes.add(n2)
mst.append((weight, n1, n2))
for edge in adjacent_edges[n2]:
if edge[2] not in connected_nodes:
heappush(candidate_edge_list, edge)
return mst
글로는 엄청 복잡했던 것 같은데, 구현하니 채 10줄 정도 밖에 나오지 않습니다;;
구현은 위에서 작성한 구현 알고리즘을 그대로 따라 가시면 됩니다
먼저 candidate_edge_list 에 저장된 mst에 저장될 수 있는 후보 간선을 최소값이 작은것 부터 차례대로 불러옵니다.
만약 (weight, n1->n2) 인 간선을 뽑았을 때 새롭게 잇게 되는 노드인 n2가 아직 connected_nodes에 저장되지 않았다면?
해당 간선에 연결된 인접 정점이 '연결된 노드 집합'에 들어 있지 않으면, 해당 간선을 선택하고, 해당 간선 정보를 '최소 신장 트리(mst)'에 삽입
위에서 작성한 구현 알고리즘을 그대로 작성해 주시면 됩니다.
connected_node에 n2 노드를 추가하고 mst에 해당 간선 정보를 저장합니다.
그리고 나서 새롭게 연결된 n2에 연결되어 있는 간선들의 정보를 candidate_edge_list에 저장해 주는 겁니다.
해당 간선에 연결된 인접 정점의 간선들 중, '연결된 노드 집합(connected_nodes)' 에 없는 노드와 연결된 간선들만 간선 리스트(candidate_edge_list) 에 삽입
앞서 adjacent_edges는 모든 쌍방의 간선 정보들을 저장하고 있다고 말씀드렸죠?
여기서 노드 n2에서 시작하는 모든 간선들을 조회했을 때 각 간선들의 목적지(이어주는 노드) 노드가 이미 connected_nodes에 저장이 되어있다면? 무시해버리면 됩니다! 어차피 안쓸거니까요
저장이 안되어있는 것들만 후보 간선 리스트, candidate_edge_list에 넣어주시면 되는겁니다!
그런식으로 모든 후보 간선들이 다 제거가 되고나면 (while candidate_edge_list) 이제 최소신장트리가 완성되었다는